Support #1794
open
Weights
100%
Description
Hi team,
I have a question about applying survey weights:
When I am applying the weights do I have to do this via specific commands e.g. svy prefix in stata or is it also possible to multiply my varaible of interest with the weight to create a new weighted variable that I could then use alongside commands that cannot be combined with survey weights directly.
Thank you for your help.
Best wishes,
Caroline
Files
{kind=link}
 Updated by Understanding Society User Support Team over 3 years ago
Updated by Understanding Society User Support Team over 3 years ago
- Status changed from New to Feedback
- % Done changed from 0 to 50
Hello,
If you want to correctly compute standard errors taking into account the sample design then you should use svyset. If you just want to apply weights then you can use the [pweight = name of weight variable] option that most Stata estimation methods allow. What is the estimation method you want to use which does not allow svyset or pweight option?
Best wishes,
Understanding Society User Support Team
Updated by Understanding Society User Support Team over 3 years ago
- Private changed from Yes to No
 Updated by Caroline Kienast von Einem over 3 years ago
Updated by Caroline Kienast von Einem over 3 years ago
Hi,
this is helpful thank you.
I am looking to use generalized estimating equations (in stata command: xtgee) but there does not seem to be a way to use weights.
Unfortunelty the multi-level approach using svy:melogit does not converge.
Best wishes,
Caroline
Updated by Understanding Society User Support Team over 3 years ago
Stata help for xtgee says "iweights, fweights, and pweights are allowed; see weight. Weights must be constant within panel." This means you can use the "[pweight = name of your weight variable]" option but the weight must be constant within a panel, i.e., the weight cannot change for a person over time. So, you cannot use cross-sectional weights. But for longitudinal analysis the correct weight is the longitudinal weight from the last wave that you are including in your analysis, and so that will not change for an individual over time.
Updated by Caroline Kienast von Einem over 3 years ago
Hi,
thank you for your quick response.
I am hoping to do cross-sectional analysis. I am interested in differences between those moving home and those not moving. I am looking at the time period between wave 3 and 6 and want to explore these difference prior moving (wave 3) and then post move (wave 6) in two regression models.
Could you help me understand why the weight within a panel would be constant for longitudinal weights but not cross-sectional?
Can you think of any alterntaive for me to perform a weighted analysis that accounts for the household clustering and lets me analyse predictors of the outcome (housemove yes/no).
Best wishes,
Caroline
Updated by Understanding Society User Support Team over 3 years ago
Cross-sectional weights make the sample estimates generalizable to the population of that time period while longitudinal weights make the sample estimates generalizable to the intial population that has been followed over time. If you are doing a longitudinal analysis you are basically trying to estimate changes over time for the intitial population. The longitudinal weight basically accounts for bias due to design (unequal selection probability), intial wave non-response and all wave-on-wave non-response since then up until the last wave you are including in your analysis. So, it will be the same for each person over time.
Based on the information you have provided, it seems that you are going to use information before Wave 3 and after Wave 6, even if your key variable is moved or didn't move between Waves 3 & 6, you are including those who have responded in all waves. Which means you need to use longitudinal weight from the last wave you are including in your sample.
But if you are only using information collected in waves 3-6 and pooling that information, so not using any information about a person from their past or future interviews then you can use cross-sectional weights. There is more information about this in the Weighting FAQ (https://www.understandingsociety.ac.uk/sites/default/files/downloads/documentation/user-guides/mainstage/weighting_faqs.pdf).
Stata allows only longitudinal weights for xtgee as it is a panel data method. If you have more Stata related questions please check Statalist (https://www.statalist.org/) and see if someone has asked this question or you can post your own question. In the meantime I will asssign this issue to our Survey Statistician and she may provide you with more help.
Updated by Understanding Society User Support Team over 3 years ago
- Assignee changed from Understanding Society User Support Team to Olena Kaminska
Updated by Caroline Kienast von Einem over 3 years ago
Hi,
thank you very much!
Maybe I should explain this better. Let's just focus on the first model to not make it even more complicated, I want to know if people who move are different from those who do not. I am looking cross-sectionally at wave 3 data as my baseline data BUT I am including a derived variable 'move' as my outcome which is based on variable 'X_addrmov_dv' from wave 4,5 and 6 to classify indidivuals as movers and non-movers (Those that move in the coming years after my baseline data is collected). Does what your saying mean should I instead include a longitudinal weight and/or include the weight of wave 6 rather than 3?
At the moment I am attempting my svy commands with c_indinub_xw - Another question would be if 'in' would be right thing to put for the derived addrmov_dv variable as it is not entriely clear to me wether this includes proxys or selfcompletion asnwers from the variable catalogue, or whether in for interview is the most applicable.
Thank you ever so much again.
Best wishes,
Caroline
Updated by Understanding Society User Support Team over 3 years ago
- % Done changed from 50 to 80
So, you need to include all those who were interviewed in Wave 3, but you also need to observe them in Waves 4, 5 & 6 to make sure that they moved or not as the addrmov_dv variable identifies moves between postcodes across any two consecutive waves. So, if someone missed Wave 5 interview the f_addrmov_dv will be missing. So, you will need to use the longitudinal weight from Wave 6.
About whether you should use f_indinub_lw or f_indpxub_lw, that depends on what other variables you will be including in your models.
If you only include variables that are available for proxy respondents then you can use f_indpxub_lw
If you only include variables that are available for non-proxy respondents but no self-completion questions then f_indinub_lw
If only include variables that are available for non-proxy respondents but also include self-completion questions then f_indscub_lw
Updated by Caroline Kienast von Einem over 3 years ago
Good morning,
thank you for your response this is very helpful.
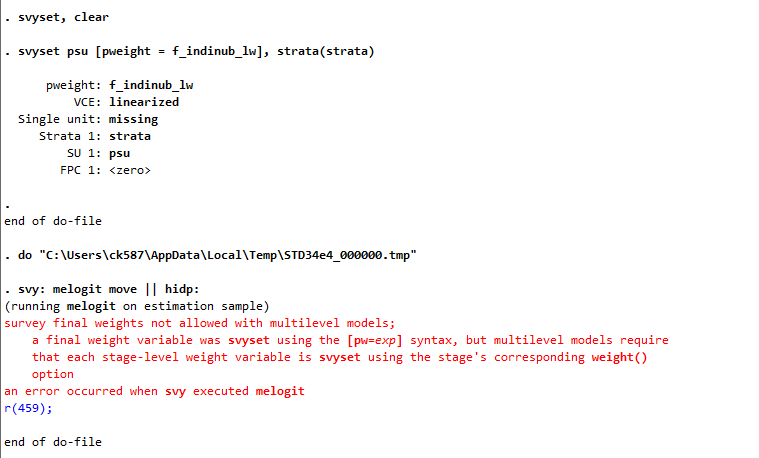
When I run the svy:melogit command with the longitudinal weight I get the error: ' survey final weights not allowed with multilevel models; a final weight variable was svyset using the [pw=exp] syntax, but multilevel models require that each stage-level weight variable is svyset using the stage's corresponding weight() option '
I wonder whether the way to resolve this would be to set it up in the svyset syntax as a 2-stage design using both individual and household level weights? In the Weighting FAQs document you talk about analyses at the individual level and analyses at the household level. However, wouldn't any analysis that is done at the individual level ought to allow for clustering by household? I understand the error from stata to pick this up but please let me know if I am reading that wrong or how best to proceed.
A second question is about the addrmov_dv variable. As you mention, it requires two consecutive waves (compared to 'x_adcts' which compares back to the last interview. Nevertheless if I look at both variables and consecutive respondents the answers are often very different e.g. adcts shows -8 (inapplicable) but addrmov_dv shows 'mover' - This made me wonder how addrmov_dv is derived and why these differences occur. Any input would be really appreciated.
Best wishes,
Caroline
Updated by Caroline Kienast von Einem over 3 years ago
- File Capture.PNG Capture.PNG added
Updated by Understanding Society User Support Team over 3 years ago
What are the different levels that you are considering in this multilevel model?
Updated by Understanding Society User Support Team over 3 years ago
Sorry I sent this too quickly. Are you considering household and individual levels in your multilevel model?
Updated by Caroline Kienast von Einem over 3 years ago
Good morning!
Households at the top level and individuals nested within the households at the lower level.
As I am not interested in change through time I have not included a lower level of observations nested within individuals - Does this change whether I should be using a longitudinal weight?
Also, reading through other forum entries it has sometimes been adviced to include psu as the highest level - Is that correct? How would I do that?
Updated by Caroline Kienast von Einem over 3 years ago
Hi,
reading in more depth I am now sure that I will need to include weights at each level of my analysis if I want to use 'melogit' / multilevel analysis and that psu should be one of the levels. My questions about observations nested within individuals from above holds but so far I would assume 3 levels:
- Psu
- Household
- Individual
Q1: What weights would be appropriate to use? Could I use nominal weight of 1 for psu and then as dicussed above 'f_indinub_lw' for the individual level?
Q1B: I know that household weights are not provided for longitudinal analyses - could you help me identify how to best create a weight for this level of my analysis?
Q2: Picking up from above - I am not really interested in change through time BUT I suppose I am following indiviuals from wave 3 to 6 to idenfty a move, so far I have not included a lower level of observations nested within individuals but would it make sense to? If I am not including observations within individuals (and therefore a time element) would it still make sense to use a longitudinal weight?
Best wishes,
Caroline
 Updated by Olena Kaminska over 3 years ago
Updated by Olena Kaminska over 3 years ago
Caroline,
Firstly, I can confirm that you need a longitudinal weight. This is because those people who moved but dropped out between waves 3 and 6 are nonrespondents, and their correction is present in longitudinal wave 6 weight, but not in cross-sectional weight 3 weight. Any cross-sectional weight will be wrong for this analysis as you take information from multiple waves (3 to 6) to learn about their move.
Your best option would be to use [pweight=...] instead of svyset and svy: commands. Try to use longitudinal weight from wave 6 for a weight - you should not be getting an error message.
Clustering is taken into account as a level in multilevel models. Make use to specify PSU at a higher level. Think very carefully about household level - how do you define if some people in a household move and others stay versus full household moving? Use a household level from one wave (wave 3?), if you decide to keep it. We generally think that households are not a longitudinal concept and are generally avoided in a longitudinal analysis.
Generally you don't need to specify different weights at different levels (unless this is related specifically to your research questions, and from my reading this isn't your case).
Hope this helps,
Olena
Updated by Caroline Kienast von Einem over 3 years ago
Hi Olena,
Thank you!
Do you know whether I would need to specify running [pweight=...] instead of svyset and svy commands as:
melogit move [pweight=f_indinub_lw] || psu:
or
melogit move [pweight=f_indinub_lw] || psu: || hipd:
The first runs well, the second as been trying to converge since yesterday ~2pm.
I understand your concerns about households. I would define both, those moving with entire household as well as those splitting from a household, as movers. Because so many moves are occuring within households (icc: 0.999) I think it is important to include this dependency in the model to not inflate the assocatiations with moving. Would a 'normal' multi-level model that includes households as a level allow movers to split from the other members to become a mover?
Oh it suprises me that you say it is not necessary to specify different weights at different levels - I thought all multilevel models require specification of all clustering levels.
Always appreciate your help.
Best wishes,
Caroline
Updated by Olena Kaminska over 3 years ago
Caroline,
On the specific melogit command it is best to check Stata manual.
Your non-convergence problem is likely due to small size of household clusters (are you using only adults)? Consider studying single households separately from multiple-person households - this may help convergence.
Theoretically to specify change in household belonging you could use a cross-classified multilevel model.
You are right that multilevel models need specification of all levels of clustering. This nevertheless does not mean that you need to specify different weights at different levels to run such models.
Hope this helps,
Olena
Updated by Caroline Kienast von Einem over 3 years ago
Hi Olena,
I will check the manual yes thanks!
I am only using adukts yes so some of my household clusters are very small (include only one person). Is there another correction for this other than studying single households separately from multiple-person households?
Another question for specifying the complex study design, do I need to set a finite population correction?
Best wishes,
Caroline
Updated by Olena Kaminska over 3 years ago
Caroline,
Yes, there can be other reasons why a model does not converge.
You don't need to specify finite population correction as UK population is very large.
Thanks,
Olena
Updated by Caroline Kienast von Einem over 3 years ago
Hi,
sorry maybe I wasn't clear I was more intersted in ways to account for these small households in my model.
Amazing. One last question is then about scaling the weights. In most forum entries I have read it seems to be adviced that this is not necessary if one is only using UKLHS data but then I have also been reading some external papers (like the one below) which really emphasis the need for scaling. What would be your recommendation?
Best wishes,
Caroline
Carle, A. C. (2009). Fitting multilevel models in complex survey data with design weights: Recommendations. BMC medical research methodology, 9(1), 1-13.
Updated by Olena Kaminska over 3 years ago
Caroline,
Literature on multilevel modelling will help you with your first question.
You can skip scaling if you are using waves 3 to 6 as variation in sample size is not so significant.
Hope this helps,
Olena
Updated by Understanding Society User Support Team over 2 years ago
- Status changed from Feedback to Resolved
- % Done changed from 80 to 100